
Recently I came across an issue with SCOM 2012 availability reports which causes the bars at the top level to display incorrectly.
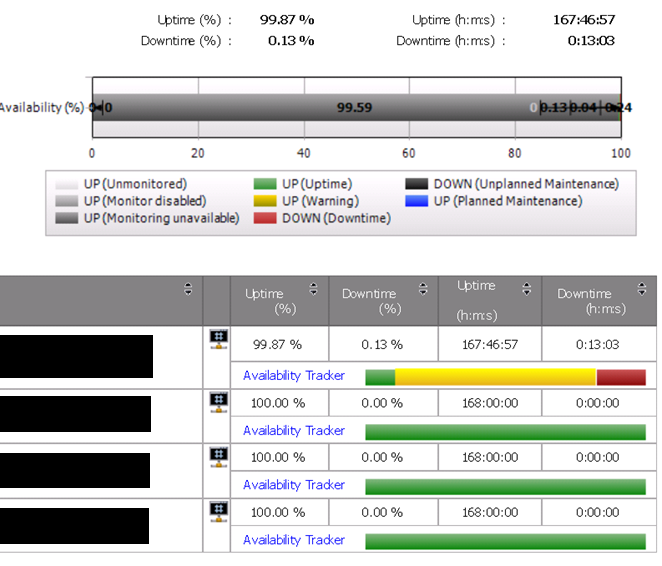
This is due to an error which is causing a duplicate entry to be created in the HealthServiceOutage table which has an outage start time but not an outage end time which causes an incorrect availability calculation for those objects..
The following SQL query will allow you to identify if you are affected by this issue:
Step 1:
SELECT * FROM HealthServiceOutage HS1 JOIN HealthServiceOutage HS2
ON HS1.StartDateTime = HS2.StartDateTime
AND HS1.ManagedEntityRowId = HS2.ManagedEntityRowId
WHERE HS2.EndDateTime IS NULL AND HS1.HealthServiceOutageRowId <> HS2.HealthServiceOutageRowId
If this query returns any records make a note of the StartDateTime values in the duplicate rows this date will be used again later to correct the problem.
This issue is addressed in UR3 for SCOM 2012 SP1 but if you are not planning on rolling this out in the near future there is a private fix available from Microsoft which will correct the relevant stored procedure. Also as this is an acknowledged known issue Microsoft will not charge for any case to address this problem.
Once you have applied the fix you will need to use the following queries to add an outage end time to the duplicate entries and then re-aggregate the affected data.
As always before performing any database update operations, ensure to make a full backup of the OperationsManager and OperationsManagerDW databases.
Step 2:
This query will update the EndDateTime value from NULL to valid time stamp.
UPDATE HS2
SET HS2.EndDateTime = HS1.EndDateTime
FROM HealthServiceOutage HS1 JOIN HealthServiceOutage HS2
ON HS1.StartDateTime = HS2.StartDateTime
AND HS1.ManagedEntityRowId = HS2.ManagedEntityRowId
WHERE HS2.EndDateTime IS NULL AND HS1.HealthServiceOutageRowId <> HS2.HealthServiceOutageRowId
Once Step 2 has finished running you should re-run the query in Step 1 to make sure that there are no additional affected rows.
Step 3:
This query will set the DirtyInd value for all the rows in the specific time range from 0 to 1, making them eligible for re-aggregation. The start date will be the StartDateTime value noted in step 1, the end date should be todays date.
update StandardDatasetAggregationHistory
set DirtyInd = 1
where DatasetId = (Select Datasetid from Standarddataset where Schemaname = ‘state’)
and AggregationDateTime => ‘2012-21-01 00:00:00’
and AggregationDateTime < ‘2012-13-03 00:00:00’
Step 4:
Disable the Standard Data set Maintenance rule for the State data set ONLY, then run the below query to manually re-aggregate the State Data.
declare @i int
set @i=1
while(@i<=500)
begin
DECLARE @DataSet uniqueidentifier
SET @DataSet = (SELECT DatasetId FROM StandardDataset WHERE SchemaName = ‘State’)
EXEC standarddatasetmaintenance @DataSet
set @i=@i+1
Waitfor delay ’00:00:05′
End
Note: Thie query may need to be run multiple times depending upon the amount of data that need to be aggregated .
Step 5:
Once this query returns less then 5 rows Step 4 can be stopped and the Standard Data set Maintenance rule can be re-enabled.
Select count(*) from StandardDatasetAggregationHistory
where Datasetid = (Select Datasetid from Standarddataset where Schemaname = ‘state’)
AND DirtyInd=1
In my case there were 741 rows that needed to be re-aggregated, on average it takes between 5 and 10 minutes for each row, which resulted in 105 hours total, although your mileage may vary depending on the power of your SQL server and how busy your environment it.
![]()